Using AWS API Gateway to display Athena query results
Created: July 1, 2023
Last updated: July 11, 2023
In a previous post we created an ETL workflow so that we could analyze traffic infringement data that we downloaded.
In this post were going to setup an API gateway with a lambda to query the Athena view and return those results so that we can build an interactive map.
Lets Begin!
First up lets start to create the API gateway infra using SST which uses the AWS CDK under the covers. I chose this so that we get live lambda development making it easier when building out serverless applications.
Lets create the API and 2 lambda functions:
- to return a list of filters that we can use to filter athena queries
- to run athena queries and return the results.
import { StackContext, Api, Function } from "sst/constructs";
export function APIStack({ stack }: StackContext) {
const searchFn = new Function(stack, 'search-fn', {
handler: 'packages/functions/src/search.go',
})
const api = new Api(stack, 'api', {
routes: {
"GET /filters": 'packages/functions/src/filters.go',
"POST /search": searchFn
}
})
stack.addOutputs({
apiUrl: api.url
})
}
As you can probably guess i've selected go as the lambda runtime for this API, but you can use any of the supported runtimes.
Using SST's API construct we can just pass through the METHOD, url and then the path to where the function code is relative to the repo's root. However for the search method were going to split this out into its own function first so that we can later add the correct permissions and environment variables that's needed for the search function.
Lets now look at creating a function for our filters endpoint. For this we're just going to hard code some values here as these will hardly change and for now don't want to keep hitting athena when data isn't changing. Lets start to create the lambda handler in packages/functions/src/filters.go
package main
import (
"encoding/json"
"github.com/rob3000/aws-etl-serverless/db"
"github.com/aws/aws-lambda-go/events"
"github.com/aws/aws-lambda-go/lambda"
)
func Handler(request events.APIGatewayV2HTTPRequest) (events.APIGatewayProxyResponse, error) {
var filters = db.FilterOptions()
if filters == nil {
return events.APIGatewayProxyResponse{
Body: `{"error":true}`,
Headers: map[string]string{
"Content-Type": "application/json",
},
StatusCode: 404,
}, nil
}
response, _ := json.Marshal(filters)
return events.APIGatewayProxyResponse{
Body: string(response),
Headers: map[string]string{
"Content-Type": "application/json",
},
StatusCode: 200,
}, nil
}
func main() {
lambda.Start(Handler)
}
There isn't too much happening with this function except for line 13 where we are calling our internal module. Its lambda best practices to move business logic outside of lambda handlers so that we can test our business logic in isolation from the lambda itself.
I'm a big user of using hexagonal architecture and you can read more about that here (Building hexagonal architectures on AWS) but for our small project we are just going to isolate the business logic from our lambda.
Back to out filters function, lets look at creating our filters logic in db/filter.go
package db
type Filters struct {
DefaultValue string `json:"defaultValue"`
Values []string `json:"values"`
}
func FilterOptions() map[string]Filters {
// Query SELECT COUNT(distinct offence_year), offence_year FROM traffic_offences_data_parquet GROUP BY offence_year
// @todo - these could come from athena.
yearArray := []string{"2023","2022","2021","2020","2019","2018","2017","2016","2015","2014","2013","2012","2011","2010",}
monthArray := []string{"Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"}
stateArray := []string{"WA", "NSW", "NT", "QLD", "VIC", "ACT", "TAS", "SA"}
return map[string]Filters{
"year": {
DefaultValue: "2023",
Values: yearArray,
},
"month": {
DefaultValue: "Jul",
Values: monthArray,
},
"state": {
DefaultValue: "WA",
Values: stateArray,
},
}
}
Now that we've got this added we can add our new stack to the sst.config.ts
import { SSTConfig } from "sst";
import { ETLStack } from './stacks/etl';
import { APIStack } from "./stacks/api";
export default {
config(_input) {
return {
name: "aws-etl-athena",
region: "ap-southeast-2",
};
},
stacks(app) {
app.setDefaultFunctionProps({
runtime: "go1.x",
});
app
.stack(ETLStack)
.stack(APIStack)
},
} satisfies SSTConfig;
we can now deploy the the new stack to aws using pnpm run deploy --stage dev.
Once its been deployed out console should look like this:
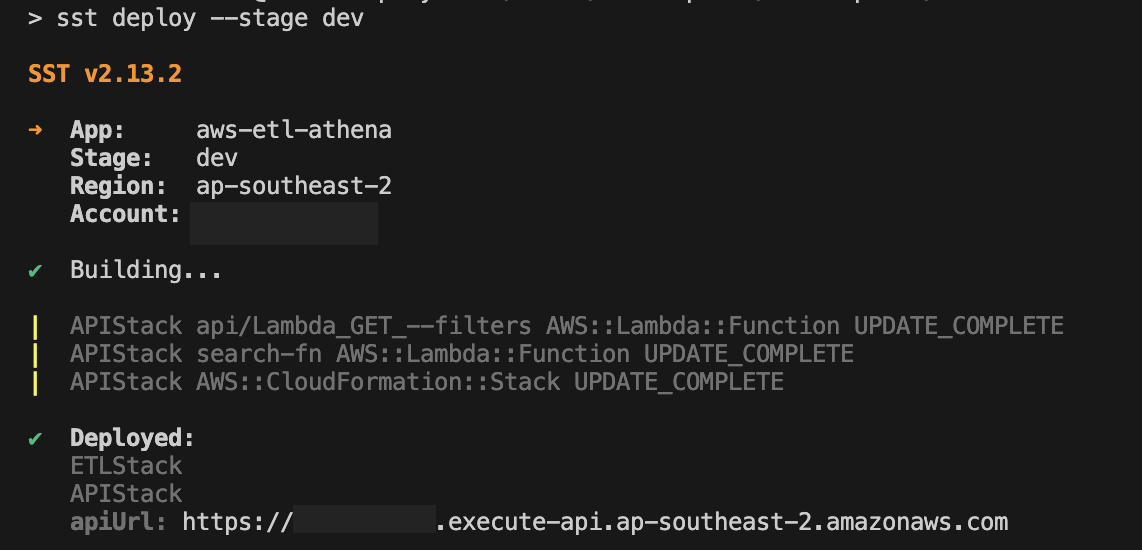
At the bottom we can see the apiUrl output which is the url we can use to hit our rest endpoint, if we were to load up postman and hit that endpoint we should get the following:
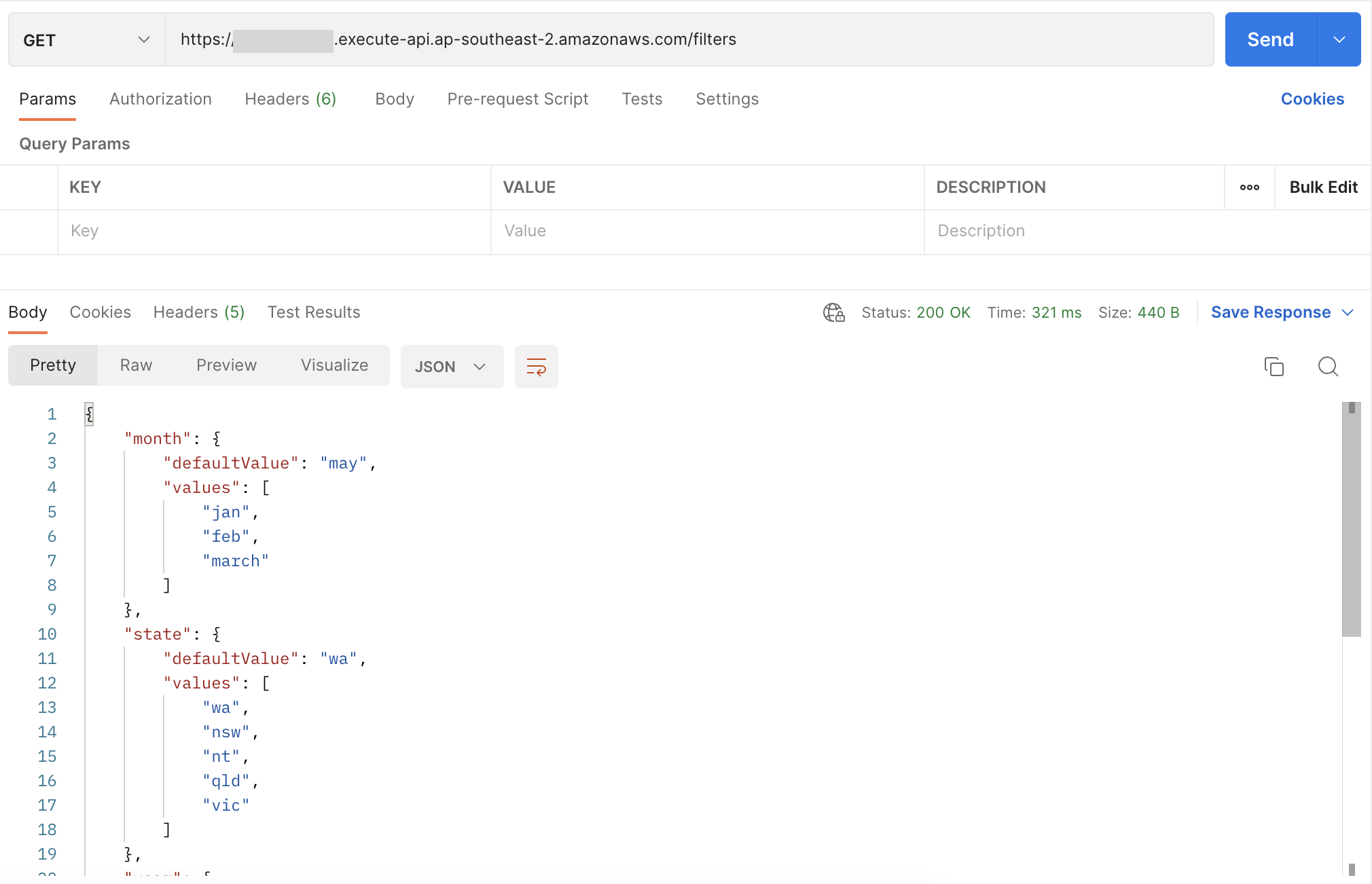
Now lets move on to the search endpoint, for this endpoint we need to update our lambda function to have the correct permissions, as AWS operates on the concept of least privilege we need the policy to be able to:
- Run athena queries
- Get the results of those queries
- Access to the S3 location of where the queries will run and data be served from.
With that it mind, lets adjust the IAM policy for our function:
const iamAccount = `${stack.region}:${stack.account}`
searchFn.addToRolePolicy(new PolicyStatement({
effect: Effect.ALLOW,
actions: [
"athena:StartQueryExecution",
"athena:GetQueryResults",
"athena:GetWorkGroup",
"athena:StopQueryExecution",
"athena:GetQueryExecution",
],
resources: [
`arn:aws:athena:${iamAccount}:workgroup/primary`,
],
}))
This now gives our function the ability to run the athena queries, but we need to expand on this some more as athena uses glue data catalog extensively we need to ensure our function can access the workgroup:
searchFn.addToRolePolicy(new PolicyStatement({
effect: Effect.ALLOW,
actions: [
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetTable",
"glue:GetTables",
"glue:GetPartition",
"glue:GetPartitions",
"glue:BatchGetPartition",
],
resources: [
`arn:aws:glue:${iamAccount}:database/traffic_camera`,
`arn:aws:glue:${iamAccount}:table/traffic_*`,
`arn:aws:glue:${iamAccount}:catalog`
],
}))
We also need to give our function to the clean bucket from the ETL solution so that it can save and retrieve the results of our queries:
const { cleanBucket } = use(ETLStack)
const searchFn = new Function(stack, 'search-fn', {
handler: 'packages/functions/src/search.go',
bind: [cleanBucket],
environment: {
S3_LOCATION: cleanBucket.bucketName,
}
})
With that setup we can look to implement the search function, we can create a file packages/functions/src/search.go and look to add the following:
package main
import (
"encoding/json"
"github.com/aws/aws-lambda-go/events"
"github.com/aws/aws-lambda-go/lambda"
"github.com/rob3000/aws-etl-serverless/db"
)
func Handler(request events.APIGatewayV2HTTPRequest) (events.APIGatewayProxyResponse, error) {
params := request.QueryStringParameters
var results = db.Search(db.SearchParams{
Year: params["year"],
Month: params["month"],
State: params["state"],
})
response, _ := json.Marshal(results)
return events.APIGatewayProxyResponse{
Body: string(response),
Headers: map[string]string{
"Content-Type": "application/json",
},
StatusCode: 200,
}, nil
}
func main() {
lambda.Start(Handler)
}
Just the same as before, not much is happening here, on line 16 to 20 we are just getting the search params that can be passed through. Now lets create the actual search logic at db/search.go and look to build our function out. The first thing were going to want to do is define our structure and just return en empty return so we know everything is all working:
package db
type SearchParams struct {
Year string `default:"2023"`
Month string
State string `default:"WA"`
}
type Result struct {
OffenceLocationCode int
CameraLocationCode int
SumInfCount int
CameraTypeOffence string
Latitude int
Longitude int
}
type SearchResult struct {
Error *string `json:"error"`
Data []map[string]string `json:"data"`
Count int `json:"count"`
}
func Search(p SearchParams) SearchResult {
return SearchResult{
Error: nil,
Data: []map[string]string{},
}
}
If we were to run our deploy command pnpm run deploy --stage dev and use postman to hit the search endpoint it should look like this:
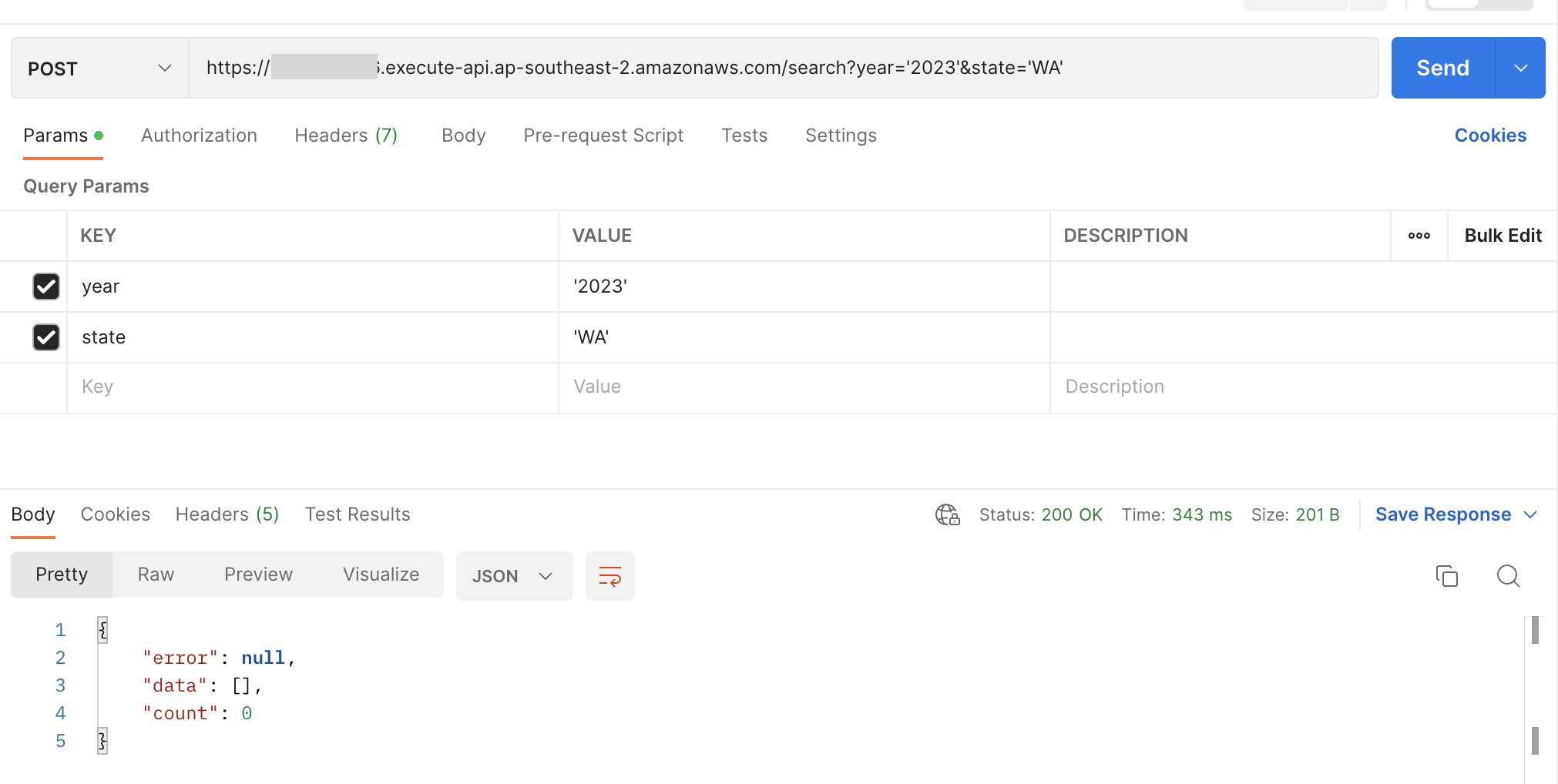
Now that we know thats all working we can now write out our query we want to hit against athena and use those params passed in via the search filters to find the data we need:
cfg, err := config.LoadDefaultConfig(context.TODO())
if err != nil {
log.Fatal(err)
}
s3Location := os.Getenv("S3_LOCATION")
if s3Location == "" {
log.Fatal("No bucket location set.")
}
var location string = fmt.Sprintf("s3://%s/Athena/", s3Location)
var query string = `SELECT
offence_location_code,
camera_location_code,
sum_inf_count,
camera_type_offence,
latitude,
longitude
FROM offences_view WHERE offence_year = ? AND rego_state = ?`
client := athena.NewFromConfig(cfg)
result, err := client.StartQueryExecution(context.TODO(), &athena.StartQueryExecutionInput{
QueryString: &query,
ExecutionParameters: []string{p.Year, p.State},
WorkGroup: aws.String("primary"),
QueryExecutionContext: &types.QueryExecutionContext{
Database: aws.String("traffic_camera"),
},
ResultConfiguration: &types.ResultConfiguration{
OutputLocation: &location,
},
ResultReuseConfiguration: &types.ResultReuseConfiguration{
ResultReuseByAgeConfiguration: &types.ResultReuseByAgeConfiguration{
Enabled: true,
MaxAgeInMinutes: aws.Int32(60),
},
},
})
if err != nil {
log.Fatal(err)
}
var queryResult *athena.GetQueryExecutionOutput
duration := time.Duration(500) * time.Millisecond // Pause for 500ms
queryExecutionId := result.QueryExecutionId
for {
queryResult, err = client.GetQueryExecution(context.TODO(), &athena.GetQueryExecutionInput{
QueryExecutionId: queryExecutionId,
})
if err != nil {
fmt.Println(err)
break
}
if queryResult.QueryExecution.Status.State == "SUCCEEDED" {
break
}
if queryResult.QueryExecution.Status.State == "FAILED" {
break
}
fmt.Println("waiting....")
time.Sleep(duration)
}
if queryResult.QueryExecution.Status.State == "SUCCEEDED" {
op, err := client.GetQueryResults(context.TODO(), &athena.GetQueryResultsInput{
QueryExecutionId: queryExecutionId,
})
if err != nil {
e := err.Error()
fmt.Println(e)
return SearchResult{
Error: &e,
Data: []map[string]string{},
Count: 0,
}
}
var rc []map[string]string
var columns []string
for _, colInfo := range op.ResultSet.ResultSetMetadata.ColumnInfo {
columns = append(columns, *colInfo.Name)
}
for i, element := range op.ResultSet.Rows {
// Skip first line which is the header
if i == 0 {
continue
}
m := make(map[string]string)
for j, el := range element.Data {
m[columns[j]] = *el.VarCharValue
}
rc = append(rc, m)
}
return SearchResult{
Error: nil,
Data: rc,
Count: len(rc),
}
}
return SearchResult{
Error: nil,
Data: []map[string]string{},
}
Now there is a lot going on with this function so lets break it down.
First up we load in the aws config so that we can use the aws athena sdk to query against.
- Lines 44 to 50 we build the S3 url that is used as part of the athena query to tell athena where to store the query results.
- Lines 52 to 59 is the query we want to run
- Lines 63 to 79 is our config to be passed to the aws sdk to run athena using
StartQueryExecution - lines 74 to 76 we add results cache for our query and set the expiry for 1 hour so that if multiple requests to athena happen they can re-use the cache for that query.
- Lines 91-109 we create a for loop to call the
GetQueryExecutionwith the ExecutionId that was returned from theStartQueryExecutioncall on lines 63-79 - Lines 112 to 150 is getting the data from the
GetQueryExecutioncall and formatting it into an array of objects using the query metadata.
With all that added we can do one last deploy with pnpm run deploy --stage dev and we can hit the search API and get the following results.
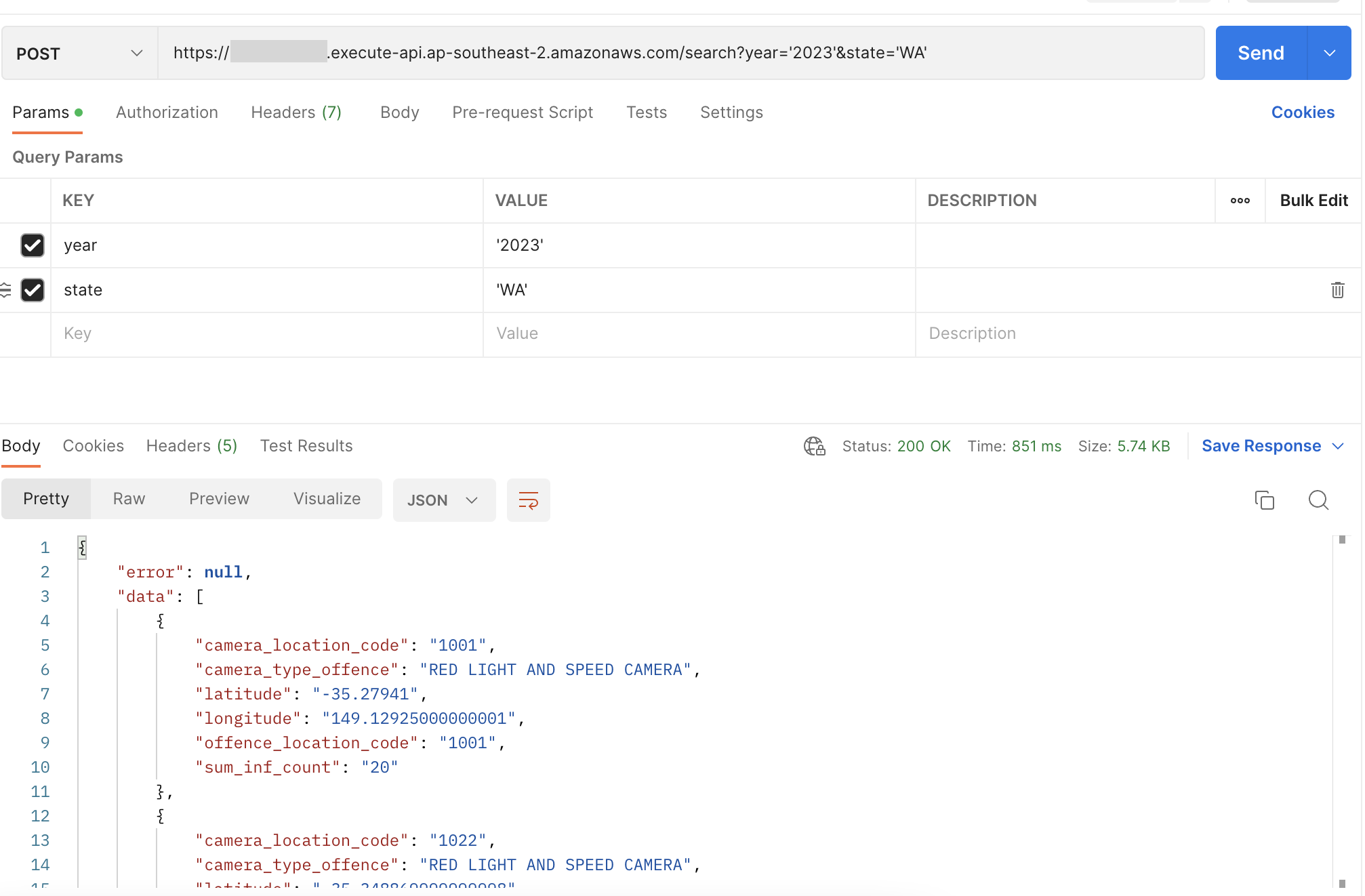
Wrap up
We've now deployed the API but there are still a few things that need some further refinement:
- Add authentication to our API
- We need to look to handle large results coming back from Athena and look to paginate those results.