Creating an ETL workflow with AWS step functions and Athena using the CDK.
Created: June 11, 2023
Last updated: July 11, 2023
In this post we are going to build an ETL solution using aws Athena workflows A.K.A AWS Step functions and we only want to use SQL only.
tl;dr: give me the code
The data
For this we going to use publicly available data from data.gov.au, more specifically:
- Traffic camera offences and fines - https://data.gov.au/dataset/ds-act-https%3A%2F%2Fwww.data.act.gov.au%2Fapi%2Fviews%2F2sx9-4wg7/details?q=
- Traffic speed camera locations - https://data.gov.au/dataset/ds-act-https%3A%2F%2Fwww.data.act.gov.au%2Fapi%2Fviews%2F426s-vdu4/
download using curl
curl -o ./traffic-speed-camera-locations.csv https://www.data.act.gov.au/api/views/426s-vdu4/rows.csv?accessType=DOWNLOAD
curl -o ./traffic-camera-offences-and-fines.csv https://www.data.act.gov.au/api/views/2sx9-4wg7/rows.csv?accessType=DOWNLOAD
Lets build!
High level solution:
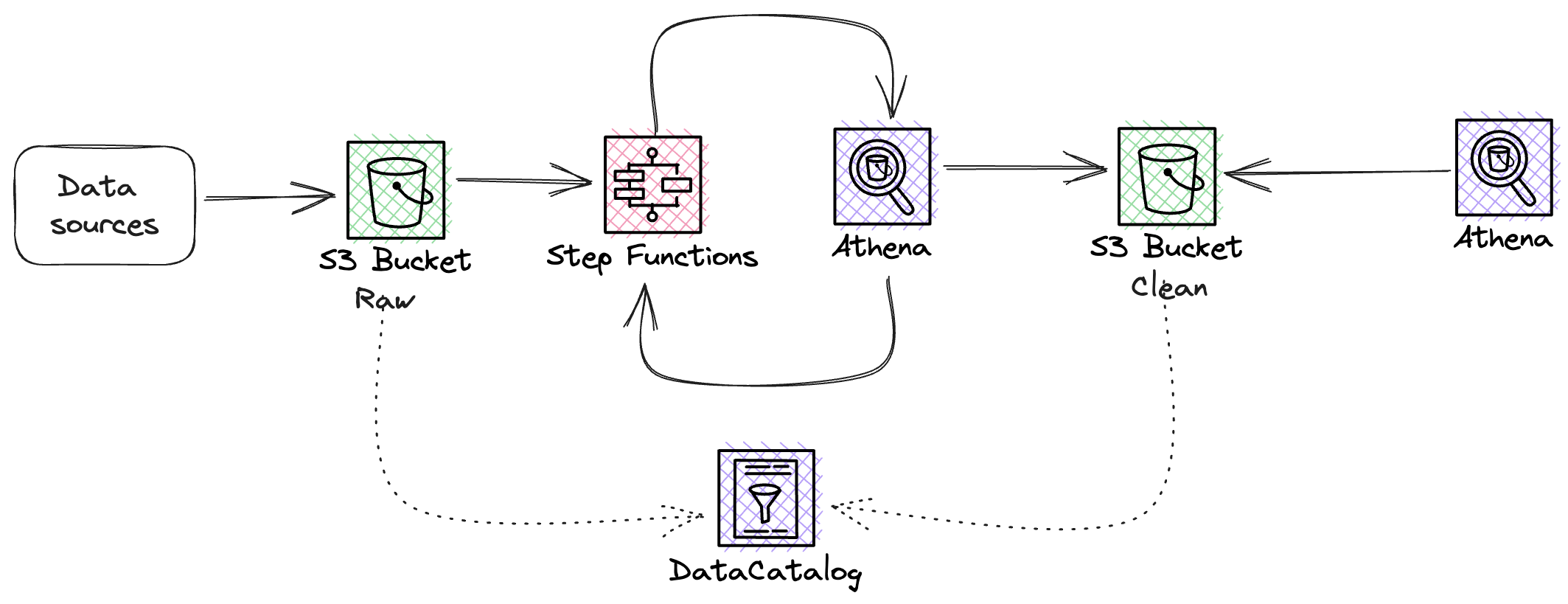
Why have 2 buckets?
raw - This is where the data gets placed into which triggers our step function to run as soon as their is new data.
clean - This is where our Glue Tables go that we can then use Athena to query the data.
Lets create these buckets using cdk
export function ETLStack({ stack }: StackContext) {
const rawBucket = new Bucket(stack, 'raw', {
name: `raw-etl-ingestion`,
});
const cleanBucket = new Bucket(stack, 'clean', {
name: `clean-etl-ingestion`,
});
We create 2 buckets so we can keep our clean data along with our glue tables from our raw ingestion. This is so that in the future we could automate the import into the raw bucket which could then trigger the step function to run. Now that we've done that were going to set a variable at the top for our DB name used throughout as well as the traffic offences data name which contains the data of the offences as well as another one for the csv for the locations.
const rawStorageName = rawBucket.bucketName
const cleanStorageName = cleanBucket.bucketName
const dbName = 'traffic_camera'
const trafficOffencesDataName = 'traffic_offences_data_csv'
const trafficCameraLocationDBName = 'traffic_speed_camera_locations_data_csv'
Next were going to set the default query execution options for the step function steps:
const defaultQueryExecution = {
workGroup: 'primary',
resultConfiguration: {
outputLocation: {
bucketName: cleanStorageName,
objectKey: 'athena',
},
},
}
Now that has been done we can create our first step by creating the glueDB
import { AthenaStartQueryExecution } from 'aws-cdk-lib/aws-stepfunctions-tasks'
const createDbSQL = `CREATE DATABASE IF NOT EXISTS ${dbName}`
// Create Glue DB
const glueDb = new AthenaStartQueryExecution(stack, 'glue-db', {
queryString: createDbSQL,
...defaultQueryExecution,
})
next we need to ensure that this step has run successfully by running the given SQL and getting the results:
const tableLookupSQL = `SHOW TABLES IN ${dbName}`
// Check to make sure the table exists.
const tableLookup = new AthenaStartQueryExecution(stack, 'run-table-lookup', {
queryString: tableLookupSQL,
integrationPattern: IntegrationPattern.RUN_JOB,
...defaultQueryExecution,
})
// Get lookup query results
const lookupResults = new AthenaGetQueryResults(stack, 'lookup-results', {
queryExecutionId: JsonPath.stringAt('$.QueryExecution.QueryExecutionId'),
})
Now were going to write out SQL to create our raw table for the traffic-camera-offences-and-fines.csv file, we first want to provide the column names and types but also tell athena how to parse different data formats.
const createDataSQL = `
CREATE EXTERNAL TABLE ${dbName}.${trafficOffencesDataName}(
offence_month string,
rego_state string,
cit_catg string,
camera_type string,
location_code int,
location_desc string,
offence_desc string,
sum_pen_amt int,
sum_inf_count int,
sum_with_amt int,
sum_with_count int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://${rawStorageName}/traffic_offences/data/' TBLPROPERTIES ('skip.header.line.count'='1')`
// Create our data table.
const createDataTable = new AthenaStartQueryExecution(
stack,
'create-data-table',
{
queryString: createDataSQL,
...defaultQueryExecution,
integrationPattern: IntegrationPattern.RUN_JOB,
}
)
Because csv files don't support block compression we need to tell Athena that correct input and output format and ensure that each column matches the record in the csv. To do so
we use the INPUTFORMAT set as org.apache.hadoop.mapred.TextInputFormat and OUTPUTFORMAT as org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat.
Now were going to do the same with our locations lookup csv and create the lookup table
const createLookupTableSQL = `
CREATE EXTERNAL TABLE ${dbName}.${trafficCameraLocationDBName} (
camera_type string,
camera_location_code int,
location_code string,
latitude string,
longitude string,
location_desc string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://${rawStorageName}/traffic_camera_locations/lookup/' TBLPROPERTIES ('skip.header.line.count'='1')`
const createLookupTable = new AthenaStartQueryExecution(
stack,
'create-lookup-table',
{
queryString: createLookupTableSQL,
integrationPattern: IntegrationPattern.RUN_JOB,
...defaultQueryExecution,
}
)
With our data being in we can actually query the csv manually if we wanted to:
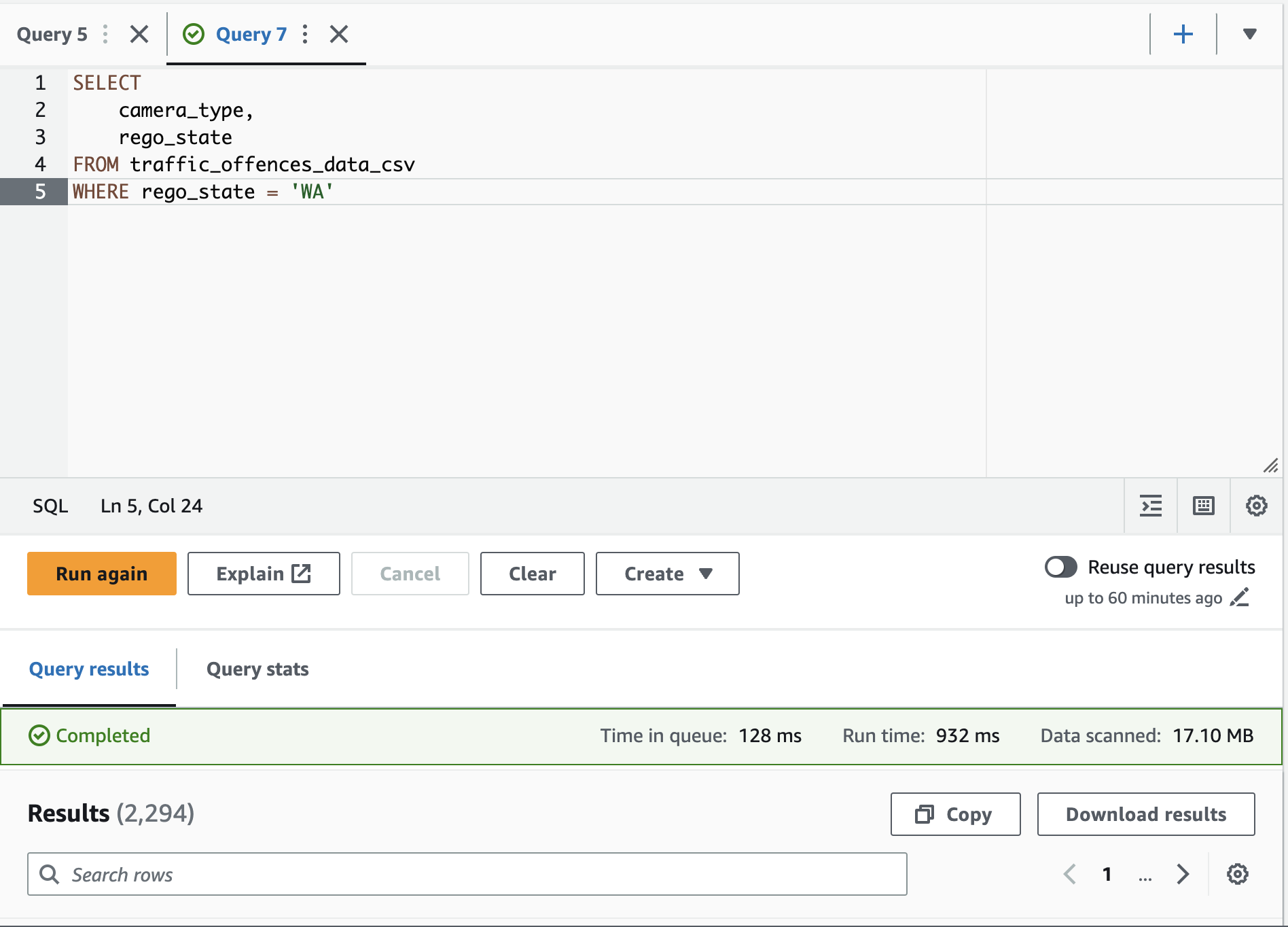
However from a cost and performance benefit we are going to convert our table to parquet formatted tables that we can partition the data so that when athena queries the data its less for it to scan thus faster and cost effective. We're going to do the same as before as set a variable with out new parquet table names so we can use them.
const parquetDataTable = `traffic_offences_data_parquet`
const parquetLookupTable = `traffic_camera_locations_lookup_parquet`
const createParquetTableDataSQL = `
CREATE TABLE IF NOT EXISTS ${dbName}.${parquetDataTable} WITH (
format='PARQUET',
parquet_compression='SNAPPY',
partitioned_by=array['offence_month','offence_year'],
external_location = 's3://${cleanStorageName}/traffic_offences/optimized-data/'
) AS SELECT
offence_month as offence_date_raw,
rego_state,
cit_catg,
camera_type,
location_code,
location_desc,
offence_desc,
sum_pen_amt,
sum_inf_count,
sum_with_amt,
sum_with_count,
substr("offence_month", 1,3) AS offence_month,
substr("offence_month", 5,5) AS offence_year
FROM ${dbName}.${trafficOffencesDataName}
`
const createParquetDataTable = new AthenaStartQueryExecution(
stack,
'create-parquet-table-data',
{
queryString: createParquetTableDataSQL,
...defaultQueryExecution,
}
)
Here you can see that we set the format as PARQUET thats also snappy compressed and we've also set up some partitioned params to partition our data by month and year. If we were to query this new table we should now see the performance benefits
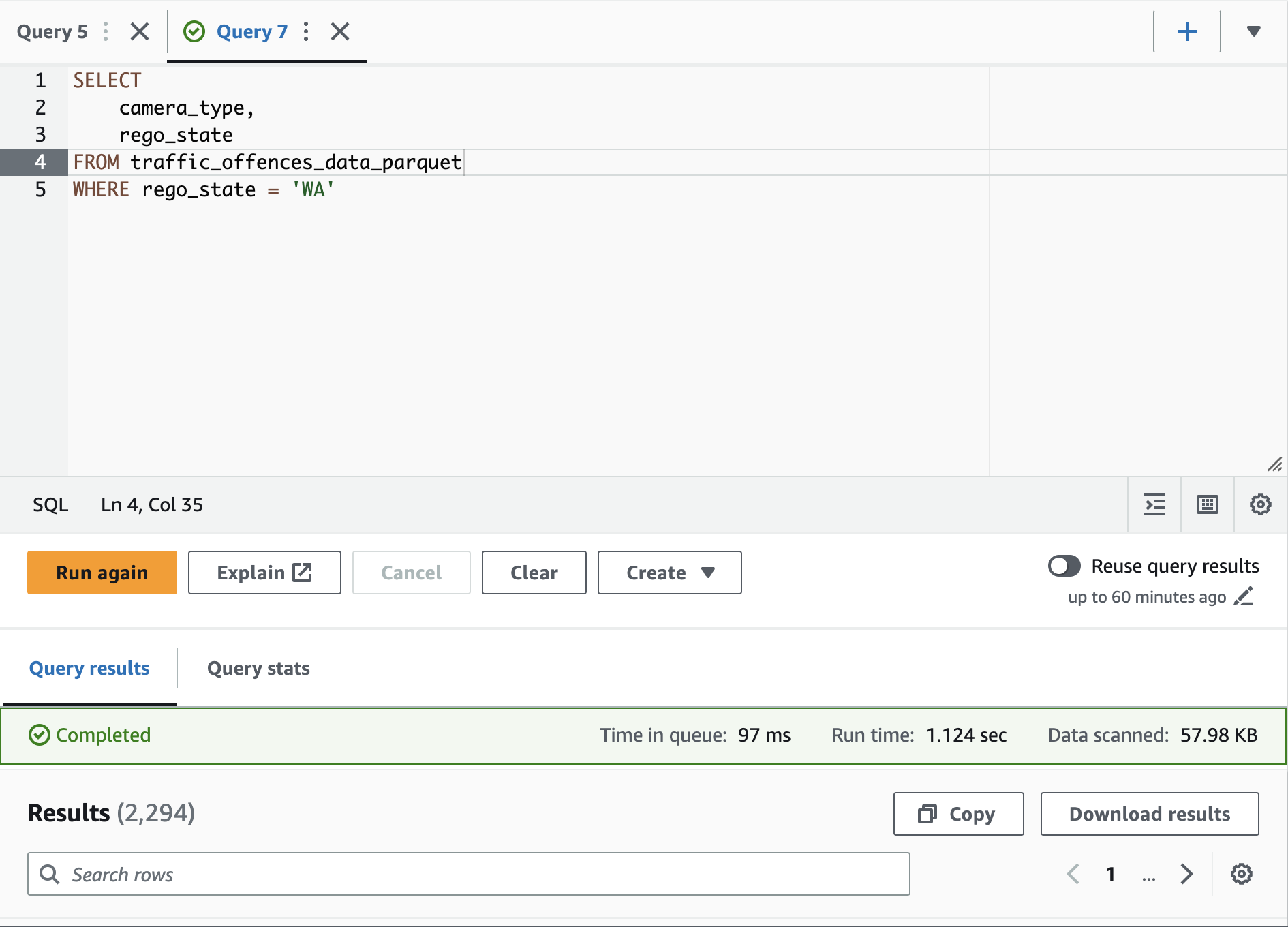
Next is our lookup table
const createParquetLookupTableDataSQL = `
CREATE TABLE IF NOT EXISTS ${dbName}.${parquetLookupTable} WITH (
format='PARQUET',
parquet_compression='SNAPPY',
external_location = 's3://${cleanStorageName}/traffic_camera_locations/optimized-data-lookup/'
) AS SELECT
camera_type,
camera_location_code,
location_code,
latitude,
longitude,
location_desc
FROM ${dbName}.${trafficCameraLocationDBName}`
const createParquetLookupDataTable = new AthenaStartQueryExecution(
stack,
'create-parquet-lookup-table-data',
{
queryString: createParquetLookupTableDataSQL,
...defaultQueryExecution,
}
)
Now that we have setup our base tables of the location data and the offences were going to create a view that we can query to aggregate the data for us:
const createViewSQL = `
CREATE OR REPLACE VIEW offences_view AS SELECT
a.*,
lkup.*
FROM (
SELECT
datatab.camera_type as camera_type_offence,
rego_state,
offence_month,
offence_year,
datatab.location_code as offence_location_code,
SUM(sum_pen_amt) AS sum_pen_amt,
SUM(sum_inf_count) AS sum_inf_count
FROM ${dbName}.${parquetDataTable} datatab
WHERE datatab.rego_state is NOT null
GROUP BY datatab.location_code, offence_month, offence_year, datatab.camera_type, rego_state
) a,
${parquetLookupTable} lkup WHERE lkup.camera_location_code = a.offence_location_code
`
const createView = new AthenaStartQueryExecution(stack, 'create-view', {
queryString: createViewSQL,
...defaultQueryExecution,
queryExecutionContext: {
databaseName: dbName,
},
})
That's all that's needed to setup the tables, but we also want to include a step in our step function for when new offences arrive so we can keep that table up to date monthly. Were going to add a Map state to our step function to check the tables and inset new data if the table checks match:
const insertDataSQL = `
INSERT INTO ${dbName}.${parquetDataTable}
SELECT
offence_month as offence_date_raw,
rego_state,
cit_catg,
camera_type,
location_code,
location_desc,
offence_desc,
sum_pen_amt int,
sum_inf_count int,
sum_with_amt int,
sum_with_count int,
substr(\"offence_date_raw\",1,3) offence_month,
substr(\"offence_date_raw\",4,5) AS offence_year
FROM ${dbName}.${trafficOffencesDataName}
`
// Insert data.
const insertNewParquetData = new AthenaStartQueryExecution(
stack,
'insert-parquet-data',
{
queryString: insertDataSQL,
...defaultQueryExecution,
}
)
Now that we have all our steps ready we can wit up the step function in the correct order we need it
const passStep = new Pass(stack, 'pass-step');
const checkAllTables = new Map(stack, 'check-all-tables', {
inputPath: '$.ResultSet',
itemsPath: '$.Rows',
maxConcurrency: 0,
}).iterator(
new Choice(stack, 'CheckTable')
.when(
Condition.stringMatches('$.Data[0].VarCharValue', '*data_csv'),
passStep
)
.when(
Condition.stringMatches('$.Data[0].VarCharValue', '*data_parquet'),
insertNewParquetData
)
.otherwise(passStep)
)
const logGroup = new LogGroup(stack, 'etl-log-group', {
retention: RetentionDays.TWO_WEEKS
})
const sfn = new StateMachine(stack, 'process-data', {
logs: {
includeExecutionData: true,
level: LogLevel.ALL,
destination: logGroup
},
stateMachineName: 'athena-etl',
stateMachineType: StateMachineType.STANDARD,
definition: Chain.start(
glueDb.next(
tableLookup
.next(lookupResults)
.next(
new Choice(stack, 'first-run', {
comment: 'Sets up for the first time to ensure we have everything we need.',
})
.when(
Condition.isNotPresent('$.ResultSet.Rows[0].Data[0].VarCharValue'),
createDataTable.next(
createLookupTable.next(
createParquetDataTable.next(
createParquetLookupDataTable.next(
createView
)
)
)
)
).when(
Condition.isPresent('$.ResultSet.Rows[0].Data[0].VarCharValue'),
checkAllTables
)
)
)
)
})
}
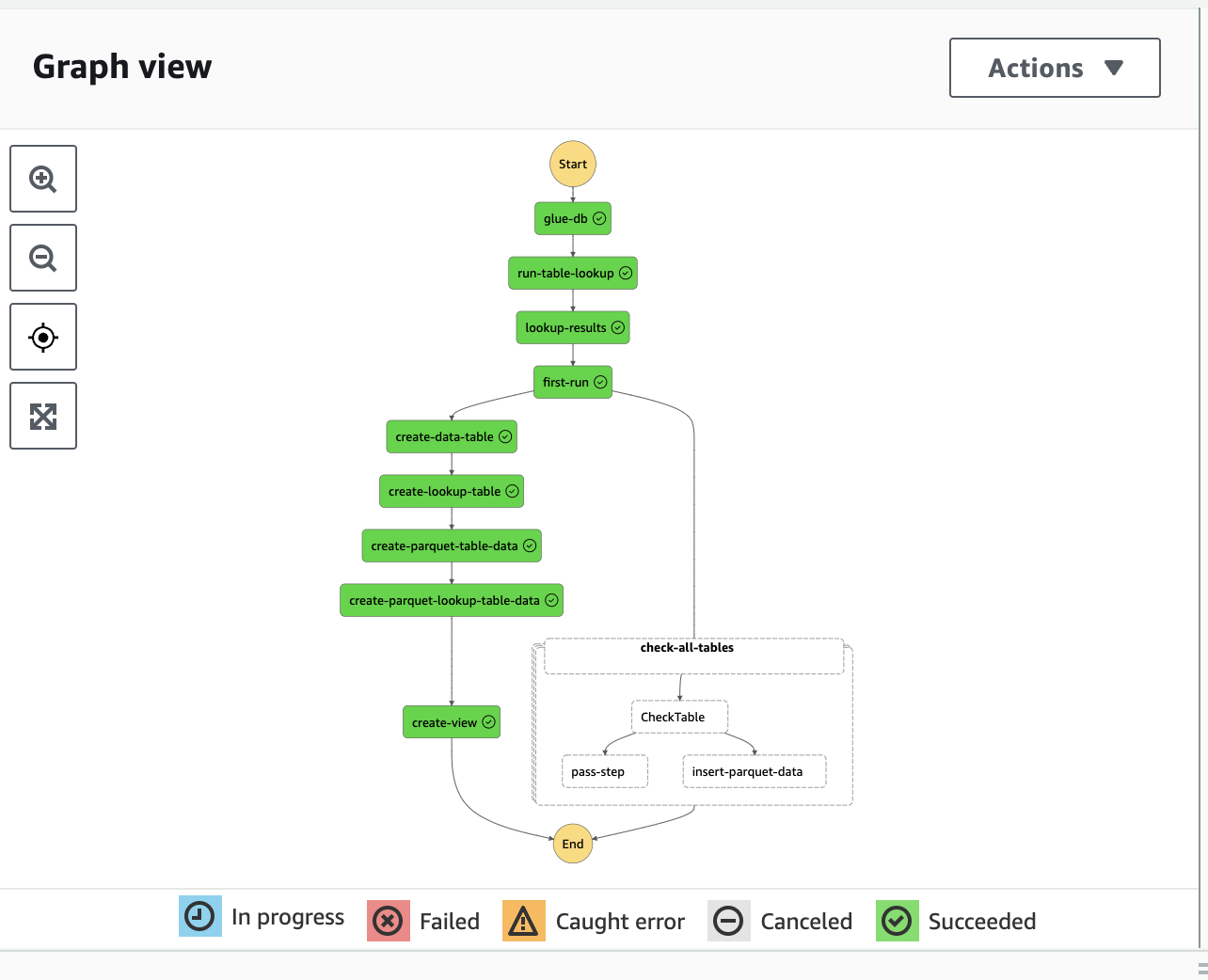
Our step function definition should look something like this:
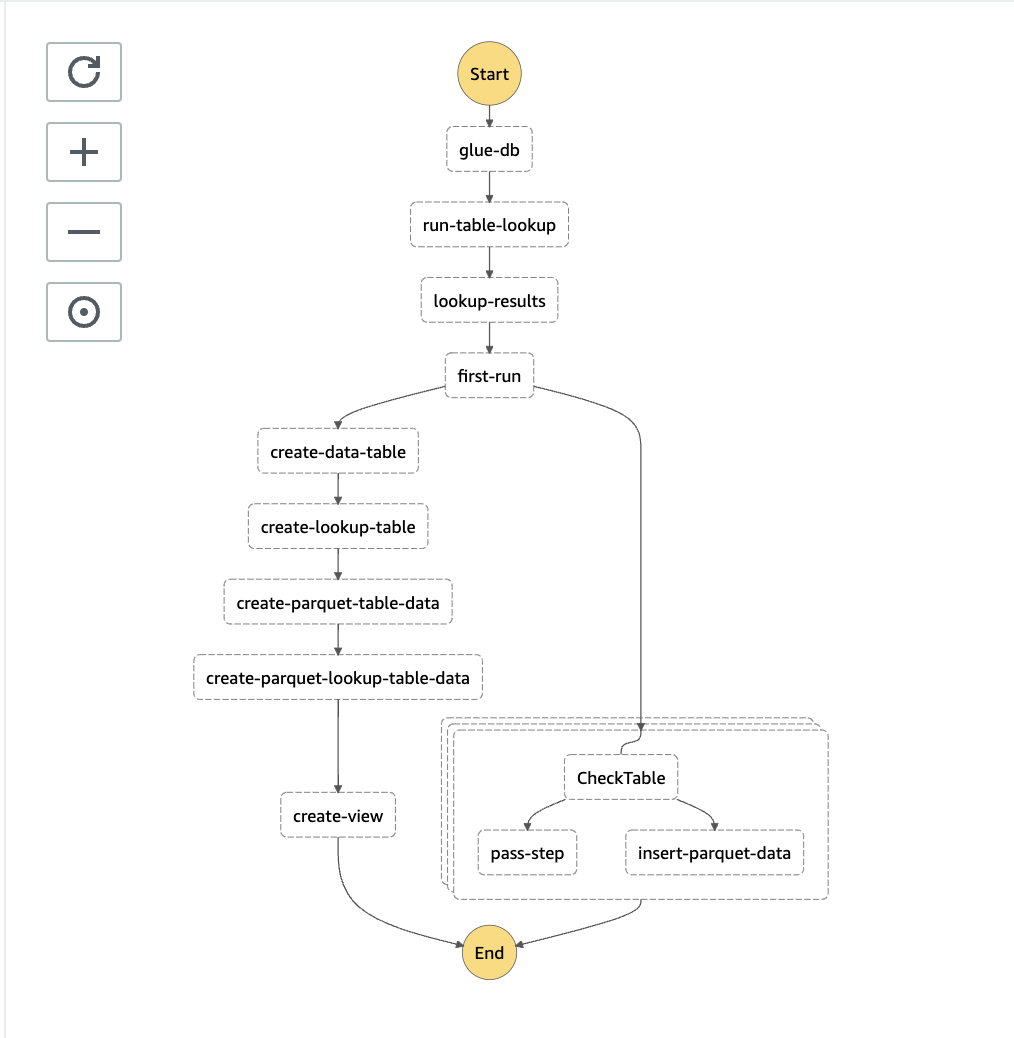
We can now look at uploading our files using the aws cli to our buckets
aws s3 cp ./traffic-speed-camera-locations.csv s3://raw-etl-ingestion/traffic_camera_locations/lookup/traffic-speed-camera-locations.csv &&
aws s3 cp ./traffic-camera-offences-and-fines.csv s3://raw-etl-ingestion/traffic_offences/data/traffic-camera-offences-and-fines.csv
With those files uploaded we can run the step function and we should now get a successful step function.
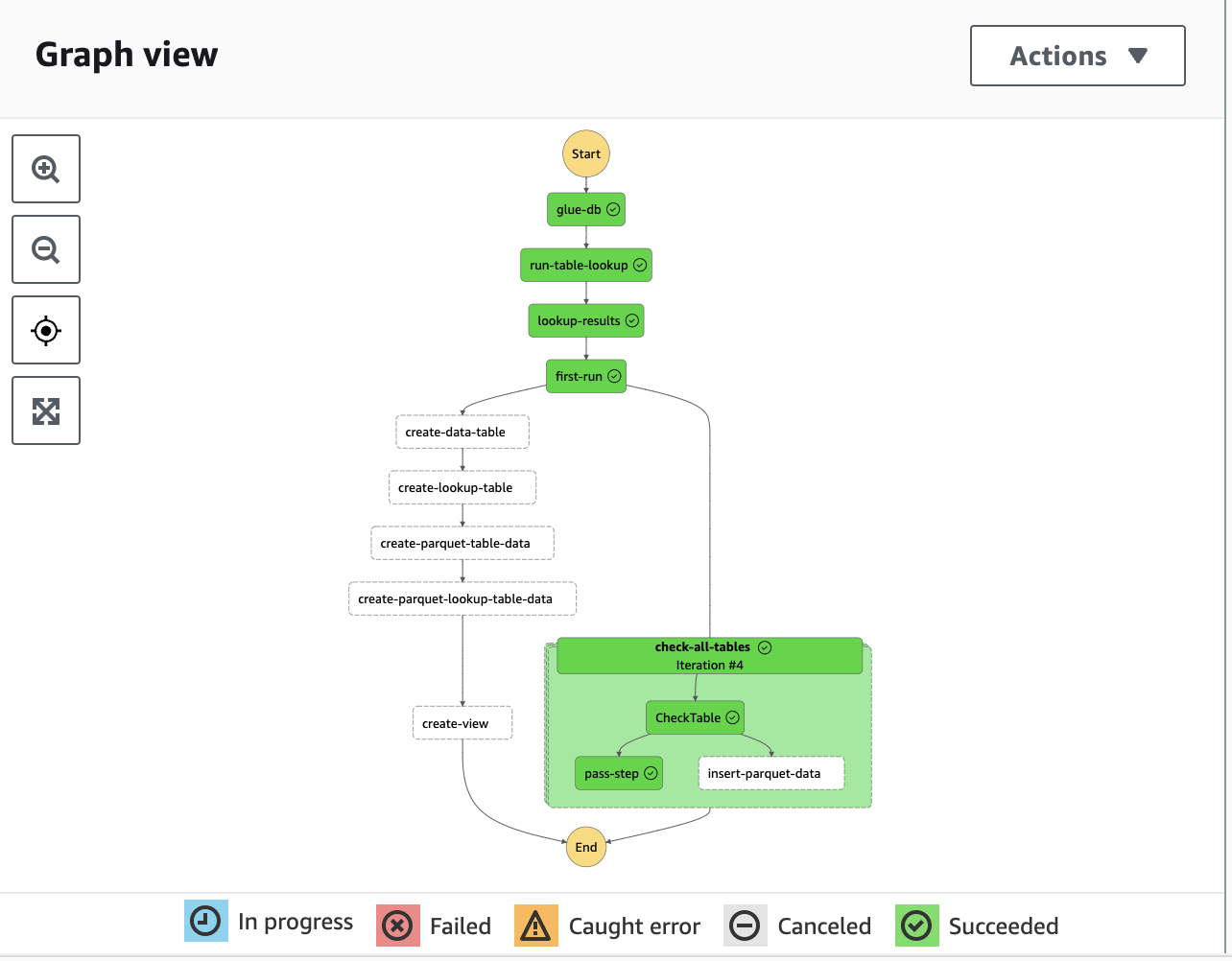
If we run the step function a second time we can see it attempting to update the parquet data table
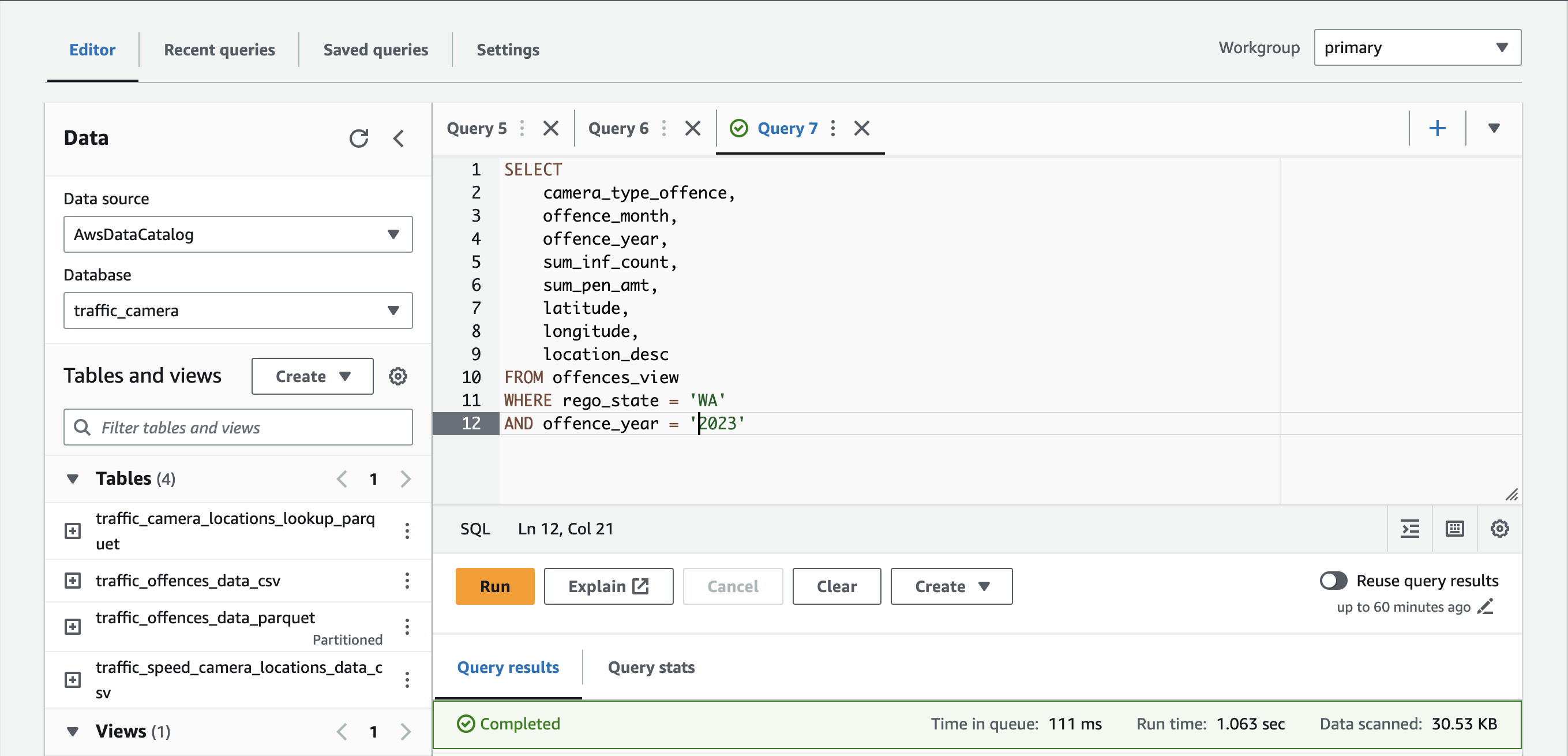
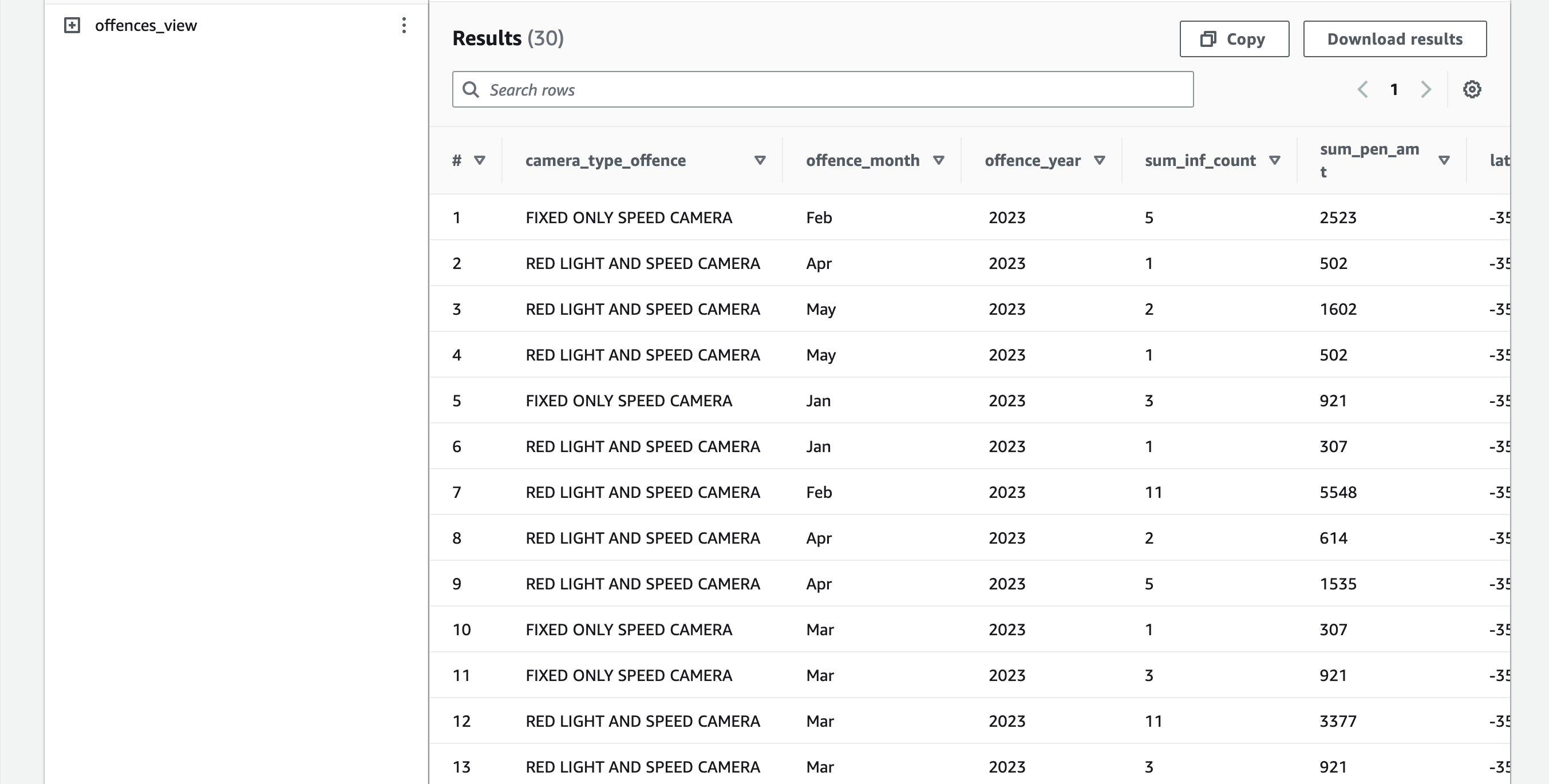
We can now query against our view to see the aggregated results of the 2 files we uploaded
And that's it! A fully managed serverless ETL workflow using only SQL